用HESSIAN时的属性丢失
在使用hessian将一个对象序列化、反序列化之后,发现原本有值的一个属性变成了NULL,观察发现在子类、父类有同名属性时会出现。
问题重现
构造测试类:
// 父类
class A implements Serializable {
public Integer a;
}
// 子类
class B extends A {
public Integer a;
}
序列化方法如下:
public static byte[] serialize(Object obj) throws IOException {
ByteArrayOutputStream os = new ByteArrayOutputStream();
HessianOutput ho = new HessianOutput(os);
ho.writeObject(obj);
return os.toByteArray();
}
反序列化方法如下:
public static Object deserialize(byte[] by) throws IOException {
ByteArrayInputStream is = new ByteArrayInputStream(by);
HessianInput hi = new HessianInput(is);
return hi.readObject();
}
测试代码:
@Test
public void testHessian() throws Exception {
B obj = new B();
obj.a = 0;
byte[] bytes = serialize(obj); // 序列化
obj = (B) deserialize(bytes); // 反序列化
System.out.println(obj.a); // null
}
原因分析
首先看序列化的过程,在构造UnsafeSerializer时会遍历类及其父类的所有属性:
protected void introspect(Class<?> cl) {
ArrayList<Field> primitiveFields = new ArrayList<Field>();
ArrayList<Field> compoundFields = new ArrayList<Field>();
// 遍历所有父类
for (; cl != null; cl = cl.getSuperclass()) {
// 通过反射获取所有的属性
Field[] fields = cl.getDeclaredFields();
for (int i = 0; i < fields.length; i++) {
Field field = fields[i];
// 忽略transient和static的变量
if (Modifier.isTransient(field.getModifiers()) || Modifier.isStatic(field.getModifiers()))
continue;
field.setAccessible(true);
// 基本类型和复杂类型分开(这段代码是不是写残了)
if (field.getType().isPrimitive() || (field.getType().getName().startsWith("java.lang.") && !field.getType().equals(Object.class)))
primitiveFields.add(field);
else
compoundFields.add(field);
}
}
ArrayList<Field> fields = new ArrayList<Field>();
fields.addAll(primitiveFields);
fields.addAll(compoundFields);
_fields = new Field[fields.size()];
fields.toArray(_fields);
_fieldSerializers = new FieldSerializer[_fields.length];
// 构造序列化实现类
for (int i = 0; i < _fields.length; i++) {
_fieldSerializers[i] = getFieldSerializer(_fields[i]);
}
}
然后,遍历序列化各个属性字段来分别进行序列化:
protected void writeObject10(Object obj, AbstractHessianOutput out) throws IOException {
// 遍历属性
for (int i = 0; i < _fields.length; i++) {
Field field = _fields[i];
out.writeString(field.getName());
_fieldSerializers[i].serialize(out, obj); // 序列化
}
out.writeMapEnd();
}
处理完的结果如下:
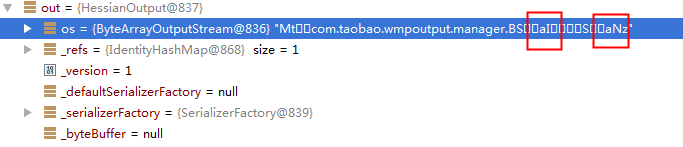
接下来看反序列化,拿到值之后设置属性:
public Object readMap(AbstractHessianInput in, Object obj) throws IOException {
// ....
// 循环读取序列化的内容。
while (!in.isEnd()) {
Object key = in.readObject();
// 相同名字的两个属性,拿到的是同一个desrializer。
FieldDeserializer deser = (FieldDeserializer) _fieldMap.get(key);
if (deser != null)
deser.deserialize(in, obj); // 在这里拿到value后设置到对应的属性中。
else
in.readObject();
}
// .....
}
序列化之后字节中对属性a有两个值,第一个非空,第二个空,那么在反序列化时会对a做两次赋值,第一次的结果为:

第二次的结果为:

到这里,就已经知道了为啥属性值会丢了。
解决方法
比较简单的办法:
- 避免在子类中出现与父类同名的属性
然并卵,现实中往往还是会出现,再想想办法:
- 找一个没有BUG得HESSION版本或者自己动手改改代码重新打个包
相对简单的改法是:在出现同名时,如果子类中已经有了,那么父类中对应属性直接忽略,代码量很少,只需要加一个continue即可,但是这样改容易挖坑。
最笨的一个解决办法是:
- 直接用Java原生的序列化方法
代码如下:
B obj = new B(); obj.setA(0); // 序列化 ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream(); ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream); objectOutputStream.writeObject(obj); // 反序列化 ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(byteArrayOutputStream.toByteArray()); ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream); obj = (B) objectInputStream.readObject(); System.out.println(obj.a); // 0
貌似原生的实现效率还是蛮高的,为啥现在都喜欢用hessian呢?